DataSource for Java 8.0.1-1186-d5c663d9 API Reference
About DataSource for Java
DataSource For Java is a Java library that allows you to build DataSource applications such as Integration Adapters. You can create applications that use Caplin's DataSource protocol to exchange financial market data in the form of structured records with other DataSource-enabled applications such as the Liberator, and to exchange trade messages and permissioning information with DataSource-enabled applications.
It is recommended that you read the DataSource Overview to gain an understanding of:
- What DataSource is and how it can be used.
- Fundamental DataSource concepts & features.
For more information on how to use DataSource for Java, navigate the links in the following table:
DataSource for Java features
DataSource for Java provides the following capabilities
- Publishing of Record Data
- Publishing of Container Data
- Publishing of Permission Data
- Publishing of Page Data
- Publishing of News headline Data
- Publishing of News story Data
- Subscription Management
- Channel-based communication to support trade messaging.
- Publishing of Generic Messages
- Publishing of JSON Messages
What is new in version 7.0
Version 7.0 of the DataSource for Java SDK is built on top of the Netty asynchronous event-driven network application framework.
The API remains the same with the following exceptions:
- The previously deprecated XML configuration has been removed, clients should convert any existing XML configuration files to the Caplin DataSource configuration format.
- The DataSourceFactory class has been removed and the methods to create a DataSource have been moved (and renamed) to the DataSource interface itself, this will require a small change to existing client code.
Getting Started
You typically use the DataSource API to integrate an external entity that provides data, into a DataSource network. The basic steps for doing this are:
-
Implement the
DataProviderinterface, to provide data that your DataSource application can send to connected DataSource peers. Your implementation would typically interface with an external entity that supplies the data. -
Create an instance of the
DataSourceclass using one of the static methods on theDataSourceclass. -
Create a
Publisher. ThePublisherpublishes messages to other DataSource peers that are connected to this DataSource, and determines the subscription management strategy (see Publishers). -
Associate an instance of your
DataProviderwith thePublisher, so that thePublisherhas a source of data that it can publish. -
Start the
DataSource.
Upgrading from DataSource 6.2
DataSource for Java 7.0 is built on top of the Netty asynchronous event-driven network application framework.
Compatibility Issues
There are three compatibility issues you should be aware of when migrating to DataSource for Java 7.0.
JVM versions
Version 7.0 requires a minimum JVM version of 1.8.
XML Configuration
The previously deprecated XML configuration has been removed, clients should convert any existing XML configuration files to the Caplin DataSource configuration format, as described in the DataSource For C Configuration Syntax Reference.
Creating DataSource instances
DataSource creation has been moved to static methods on the the DataSource interface, the DataSourceFactory class has been removed.
Existing code using the DataSourceFactory create methods should be changed to call the equivalent method on the DataSource interface.
For Example:
// creation code using DataSource 6.2
DataSource datasource = DataSourceFactory.createDataSource("datasource.conf");
// creation code using DataSource 7.0
DataSource datasource = DataSource.fromConfigFile("datasource.conf");
The new DataSource creation methods are:
public static DataSource fromArgs( String[] args )
public static DataSource fromArgs( String[] args, Logger logger )
public static DataSource fromConfigFile( String configFileName )
public static DataSource fromConfigFile( String configFileName, Logger logger )
public static DataSource fromConfigString( String configString )
public static DataSource fromConfigString( String configString, Logger logger )
Configuring your DataSource application
DataSource applications are configured using the Caplin DataSource Configuration Format as described in the DataSource For C Configuration Syntax Reference.
Using DataSource Peers
A DataSource application is bi-directional - it can send and
receive data from another DataSource application. In addition, a DataSource
can either connect to, or listen for connections from, another DataSource.
These other DataSource applications are referred to as Peers.
Caplin Liberator and Caplin Transformer are examples of DataSource peers.
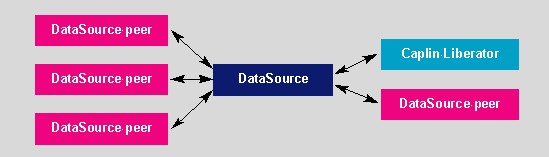
DataSource messages are often referred to as "objects" when handled by a DataSource application; Liberator documentation refers to objects in this way. Objects can be requested from individual DataSource peers or groups of peers.
Active DataSources
An active DataSource is one that will service requests for objects (the opposite of this is a broadcast DataSource, which simply sends all objects and updates to its peers regardless). It is an active DataSource's responsibility to keep track of which objects have been requested and send updates for those objects only.
When a StreamLink user requests an object, and Caplin Liberator does not already have it, Liberator requests it from one or more of its active DataSource peers. If another user subsequently requests that object, Caplin Liberator will already have all the information it needs, and will respond to the user's request immediately.
Objects may be discarded as well as requested. This tells the DataSource that the sender of the discard request no longer wishes to receive updates for the object. When a user logs out or discards an object, Caplin Liberator sends a discard message to the active DataSource (as long as no other user is subscribed to that object). The object will actually be discarded by the DataSource one minute after the user requested the discard; this prevents objects being requested and discarded from the supplying DataSource unnecessarily.
Publishers
The API includes several types of Publisher that implement the
Publisher interface. You create an instance of a particular
Publisher by calling a createXXXPublisher() method on the
DataSource instance.
Active Publisher
The ActivePublisher passes all
subscription requests from remote DataSource peers to the DataProvider,
but only passes a discard when all of the remote peers have discarded the subject.
The DataProvider implementation is not responsible for keeping
track of the number of requests received; it just needs to stop supplying data
for a subject when it receives the single discard.
Broadcast Publisher
The BroadcastPublisher publishes
messages to all connected DataSource peers. The use of a BroadcastPublisher
is not recommended due to the detrimental effects that broadcast data has on
reliable and predictable failover between DataSource components.
Compatibility Publisher
The CompatibilityPublisher is
provided for backwards compatibility with DataSource applications that use
versions of DataSource for Java older than 6.0.
This publisher is similar to ActivePublisher except that it
passes a discard to the DataProvider every time a peer discards
a subject, rather than a single discard when the last peer discards the
subject. This requires the DataProvider to do more work, by
keeping count of how many peers are subscribed to each subject and only
unsubscribing from the back end system when the last peer discards the
subject.
Namespaces
A namespace determines which particular subjects can have their data
published by a given Publisher. The rules defining what
subjects are in a particular namespace are determined by implementations of
the Namespace interface. A
Namespace instance is associated with a Publisher
when you call the createXXXPublisher() method on the
DataSource. The Publisher uses
the Namespace to ensure that its associated
DataProvider only receives requests for subjects in a specified
namespace.
You can write your own implementation of Namespace, but the
API provides some ready-made implementations that should be suitable for
most situations - see PrefixNamespace
and RegexNamespace
For example, PrefixNamespace ensures that data is only
published if its subject matches the specified prefix. So, if the prefix
supplied in the constructor for an instance of PrefixNamespace
is " /I/ ", data with the subject " /I/VOD.L " will be published, whereas
data with the subject "/R/VOD.L " will not be published.
Example showing the DataSource, Publisher, DataProvider and Namespace
This example shows how to create a DataSource instance and create a
broadcast publisher for sending updates.
import java.util.logging.Level;
import java.util.logging.Logger;
import com.caplin.datasource.ConnectionListener;
import com.caplin.datasource.DataSource;
import com.caplin.datasource.PeerStatusEvent;
import com.caplin.datasource.messaging.record.RecordType1Message;
import com.caplin.datasource.namespace.PrefixNamespace;
import com.caplin.datasource.publisher.BroadcastPublisher;
public class OverviewExample implements ConnectionListener
{
private static final Logger logger = Logger.getAnonymousLogger();
public static void main(String[] args)
{
new OverviewExample();
}
public OverviewExample()
{
// Create an argument array. In practice these would probably be the command line arguments.
String[] args = new String[1];
args[0] = "--config-file=etc/datasource.conf";
// Create a Datasource.
DataSource datasource = DataSource.fromArgs(args, logger);
// Register as a connection listener
datasource.addConnectionListener(this);
// Create a broadcast publisher with a NameSpace that will match everything.
BroadcastPublisher publisher = datasource.createBroadcastPublisher(new PrefixNamespace("/"));
// Now start the DataSource.
datasource.start();
// Updates can be broadcast using the publisher, for example a record:
RecordType1Message record = publisher.getMessageFactory().createRecordType1Message("/BROADCAST/MYRECORD");
record.setField("FieldName", "FieldValue");
publisher.publishInitialMessage(record);
}
@Override
public void onPeerStatus(PeerStatusEvent peerStatusEvent)
{
logger.log(Level.INFO, String.format("Peer status event received: %s", peerStatusEvent));
}
}
Example Applications
One of the best ways to gain an understanding of how to use the DataSource for Java API is to look at some example DataSource applications. The Caplin Integration Suite kit includes three example applications that illustrate best practice when using the DataSource for Java API, plus a migration example that shows how to upgrade an existing DataSource application to use the version 6.0 API.
The example applications use two notional companies to illustrate a typical use case for DataSource for Java:
NovoBankis a bank or financial institution that wishes to build a trading application using Caplin Products. The NovoBank developers will be responsible for writing the Integration Adapter using the DataSource for Java API. The DataSource will communicate with an external trading system provided byXyzTrade.XyzTradeis an external company that provides an order management system and streaming rates. XyzTrade provides NovoBank with an API to request rates and perform trades. In practice the XyzTrade API would be a "black box", but for the purpose of these examples the source code for the XyzTrade system is provided.
The three example applications perform the following roles:
NovoDemoSourceis a DataSource application that shows how to receive requests from peers and send data in response. The application demonstrates the usage of all three types ofPublisher.NovoDemoSinkis a DataSource application that shows how to subscribe to data that is broadcast from another DataSource.NovoChannelSourceis a DataSource application that shows how to perform bi-directional communication with a StreamLink client; for example, to exchange trade messages.
Viewing the Example Source
The three example applications all contain an src folder containing
the source code. Source code is also provided for the XyzTrade system.
Running the Example Application Binaries
Each of the example applications is provided as an executable JAR. To run
the application, navigate to the relevant application directory in the examples
folder and execute the JAR within the lib folder. For example:
cd {KIT_ROOT}/examples/demosource
java -jar lib/datasource-java-demosource-{VERSION}.jar
Note that the example folders all contain an etc folder containing
the DataSource configuration file and fields configuration file. In order for
the example applications to successfully start up, you will need to set up and
correctly configure a Caplin Liberator, and then edit the DataSource configuration
file to reference your Liberator installation.
Latency Chaining
Datasource for Java supports latency chaining both as a latency chain source and as a latency chain link. For more information on latency chaining, see Record latency in record updates.
What are Latency Chains?
A latency chain is a way of measuring the latency of any given message as it
passes through connected systems. The message is timestamped at origin.
As the message is transmitted from DataSource to DataSource (and on through the Liberator),
each DataSource records an entry and exit timestamp difference.
This allows the end user to see the latency at each point in the system.
How do I start a latency chain?
Enable latency chaining by adding the following line to the configuration file:
latency-chain-enable TRUE.
The first DataSource in the chain, should call
RecordMessage.setInitialLatencyChainTime(Instant)
with the intial timestamp for the latency chain.
How do I implement a latency chain link?
The DataSource automatically handles latency chain links, if latency chaining is enabled and the initial latency chain timestamp field is present. The DataSource will then record the entry and exit time for each message.
TOPChannels that
provide a bi-directional communication mechanism between StreamLink clients and DataSource applicationsDataProvider.