Generic data
When a record contains generic data, you can send messages without configuring fields in any configuration files. This is useful for unstructured data or flexible message structures, avoiding the need to re-configure multiple files when changing data dictionaries.
| Generic records are not yet compatible with Liberator’s throttling and bursting (batching) performance optimisations. Use Type 1 Records in preference to Generic Records for subjects that have a high update rate. |
Generic records make it easy, for example, to handle trades with a variable number of legs. These messages are constructed in a DataSource application (typically in an Integration Adapter) by calling on the relevant DataSource API.
You use generic messages when:
-
There are an indeterminate number of fields coming from a system that the Caplin Platform integrates with, such as a pricing system.
-
You don’t want to manage the record’s fields in a fields.conf file.
Generic messages therefore can speed up development. The tradeoff is that generic messages are larger and take up slightly more bandwidth than the predefined fields (such as the fields in a Type 1 format record), and that they use a separate dedicated channel.
This is how they are implemented:
With Type 1-3 records, messages store a field number and its value. In order to retrieve the field name we had to access a configuration file that stored a mapping to resolve those field numbers into names:
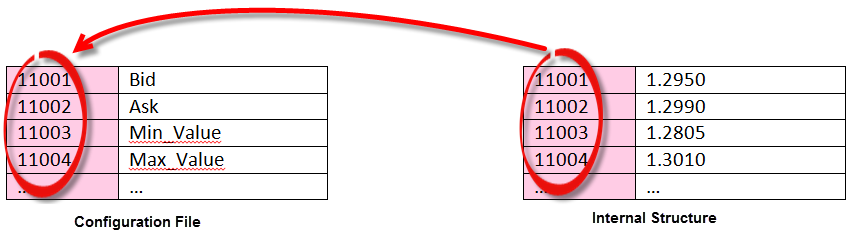
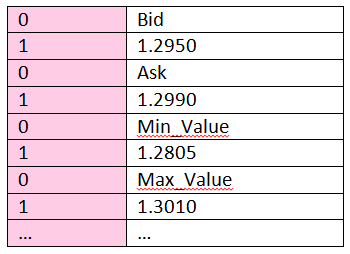
The generic message stores the field name and the value, so the intermediate step has been eliminated. Now, when requested for the list of fields inside the message, fields are returned in the following format:
See also: