Active subscription model
Active subscriptions are the most common way for Liberator and other DataSource applications to supply data.
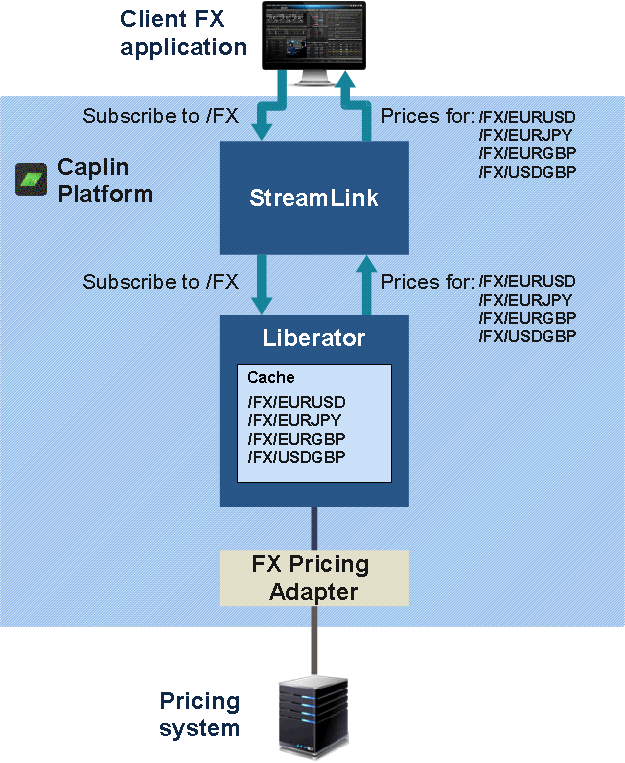
A client application subscribes, via StreamLink, to data on Liberator, by requesting a subject. If other clients have already subscribed to the same subject, Liberator already holds the data for it in its cache, so it sends an image of the cached data to the client. Liberator subsequently sends the client, and all other clients subscribed to that subject, updates to the data as they are received (but this is subject to any throttling and bursting settings that apply to the data). This is shown in the following diagram:
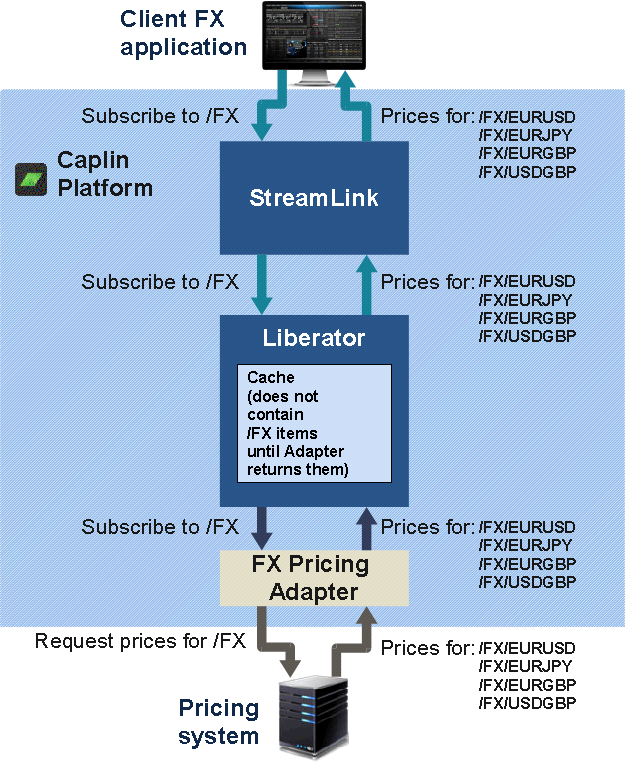
On the other hand, if the subscription request is the first one that Liberator has received for that particular subject, the data for the subject won’t be in its cache, so Liberator sends a subscription request to the DataSource applications that can supply the data. The supplying DataSource application is typically either an instance of Caplin Transformer, or an Integration Adapter that obtains the data from an external source. You usually configure Liberator to make the request through a data service.
The DataSource application is an active Datasource because it keeps track of which subjects have been requested and sends updates for those subjects only. When it receives the initial subscription request from the Liberator, it sends back the most up-to-date image of the data for the requested subject. Liberator retains this image in its cache and passes it on to the subscribing client. The DataSource application sends the Liberator all subsequent updates to the data as it receives (or generates) them. This is shown in the following diagram:
Liberator’s caching feature ensures that when multiple clients subscribe to the same subjects, the data is supplied efficiently to the clients. Since clients don’t connect directly to a source of data (only Liberator has this connection), and Liberator only subscribes to the source once for a given subject, the overall network traffic is reduced.
The Integration Adapter would also typically cache the subscription data, so that it doesn’t have to go to the Pricing system every time it receives a new request for the same data from a Liberator or Transformer.
How do active subscriptions differ from the standard publish/subscribe model?
In a pure publish/subscribe model, publishers are completely decoupled from subscribers, with a component between them linking them together. This means publishers have to constantly publish all their data. This model doesn’t always fit in with the style of the application; for example, it doesn’t work well if subscriptions are for data that needs to be created dynamically. Implementations often work round these limitations by arranging for publishers to subscribe to a known channel and listen for requests to start publishing data.
In contrast, DataSource’s active subscription mechanism allows an Integration Adapter to handle a subscription request dynamically and create a custom data stream based on the subscription details. The Adapter can then supply the data stream to the Liberator, and hence to the subscribing client.
Active subscriptions aren’t just a benefit for custom data streams; they also reduce network traffic for standard data streams, because only the streams being subscribed to by clients need to be sent between Integration Adapters and Liberator.
See also: