Containers
A container object holds a list of subject names of other objects – the elements of the container. It’s typically used to hold a list of financial instruments that the client application displays in a grid format.
The container doesn’t hold the details of the items in it. It just holds the subject names of the items - effectively a list of pointers to the items.
Example
This diagram shows a container where elements are the subject names of 200 currency pair records (/GBPUSD, /USDCAD, and so on):
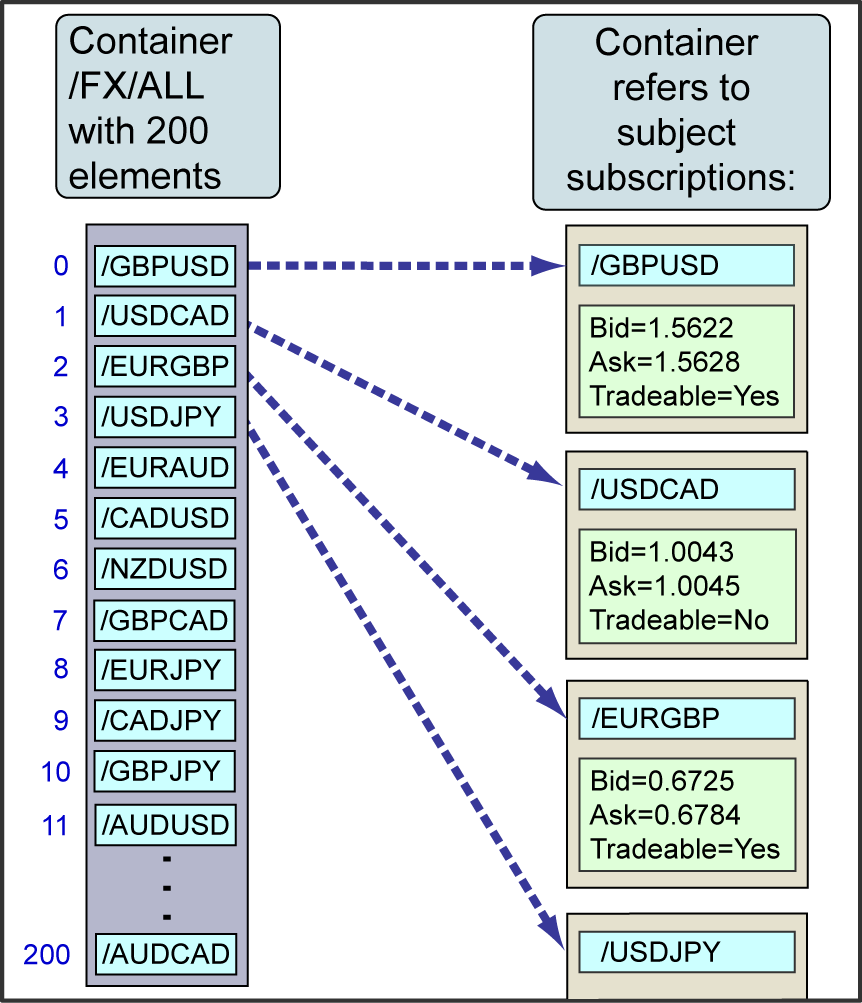
When the client application subscribes to the container (requests it via StreamLink), it’s also automatically subscribed to the subjects that the container refers to, so it receives all the updates for the corresponding records as their field values change.
The container is managed by a Liberator (and sometimes other Caplin Platform components) on behalf of all the subscribing clients. For example, the Liberator handles the addition and deletion of container elements; it automatically adjusts client subscriptions accordingly and communicates the changes to the clients.
| Automatic subscription makes it easier for client applications to manage items in a list. Alternatively, if you want to manage the list yourself, subscribe to the directory that defines it and then subscribe separately to the items in the list as required; see Directories. |
You usually define a container within an Integration Adapter; this is the Adapter that subsequently supplies instances of the container to subscribing clients. The Adapter typically interfaces to a bank system, or other external data feed, that supplies the list of items that go in the container. For example, the external system could provide a list of Fixed Income instruments that can be traded. This Adapter doesn’t have to be the same as the one that supplies the data in the container.
Container features
-
Auto subscription:
Once the client has subscribed to a container, the subjects referred to by the container’s elements are automatically subscribed to as well - you don’t have to program it yourself.
-
Changes to individual items in the container are managed by a DataSource application (typically an Integration Adapter). The updates are automatically fed to the client in the same way as if the client had explicitly subscribed to each item individually.
-
You can set up a windowed view of a container in the client, where the Window is managed by Liberator.
-
You can filter, sort and group container elements using Transformer’s Refiner Service blade. There’s no need to implement filtering and sorting algorithms in client applications.
-
The source of a container can be independent of the source of the elements in the container. (For more about this, see How can I… Obtain container data from several sources.)
-
Container snapshots:
Liberator can supply an image of a container’s contents in CSV or XLSX format, for export to spreadsheets and other data analysis software. (For more about this, see How can I… Obtain a container snapshot in a CSV or XLSX file.)
When to use containers
Use containers to hold lists of items when the items to be included in the list are determined dynamically by some external system (such as a Pricing system) and you can obtain them using a suitable Integration Adapter. They’re especially useful for displaying long lists of tabular data in client windows; this is managed by Liberator’s container windowing feature.
You can also use containers when your client application needs to filter and/or sort the contents of a list based on fields that don’t update. The filtering and sorting capabilities of Caplin Transformer's Refiner Service blade are ideal for this purpose. The client application subscribes to a container, specifying filter and sort criteria. Then the Refiner service dynamically creates a custom container that matches these criteria, and keeps the container up to date as the data within it changes.
| Avoid implementing containers with very large numbers of elements (typically more than 50,000). Although Liberator is optimised for performance and uses multiple execution threads, intensive client access to containers of this size can increase the latency of data updates to an unacceptable level. |
Container operations in DataSource APIs
The DataSource APIs allow you to perform various operations on containers.
You can:
-
Add an element to a container. The element is appended to the end of the container.
-
Insert an element into a container at a specified position.
-
Remove an existing element from a container.
-
Remove ("clear down") all elements from a container that match a specified subject prefix.
| The exact way in which your DataSource application should subscribe to and manipulate containers depends on which DataSource SDK you are using. For details, consult the API Reference document for your particular DataSource SDK. |
See also:
-
Filtering and sorting containers using Transformer’s Refiner Service blade
-
How can I… Configure container usage in Liberator
-
How can I… Create containers in an Integration Adapter
-
How can I… Obtain container data from several sources
-
How can I… Obtain a container snapshot in a CSV or XLSX file