Peer discovery
Discovery maintains a register of providers and consumers of data services, which allows DataSource applications to find and connect to each other at runtime without the necessity of using add-peer to configure connections between specific DataSources at specific network locations.
In a traditional deployment, connections between named DataSources are configured in advance using complementary pairs of add-peer configuration items, one on each side of the connection. The add-peer block of the DataSouce responsible for initiating the connection includes the network location of its peer (addr and port options).
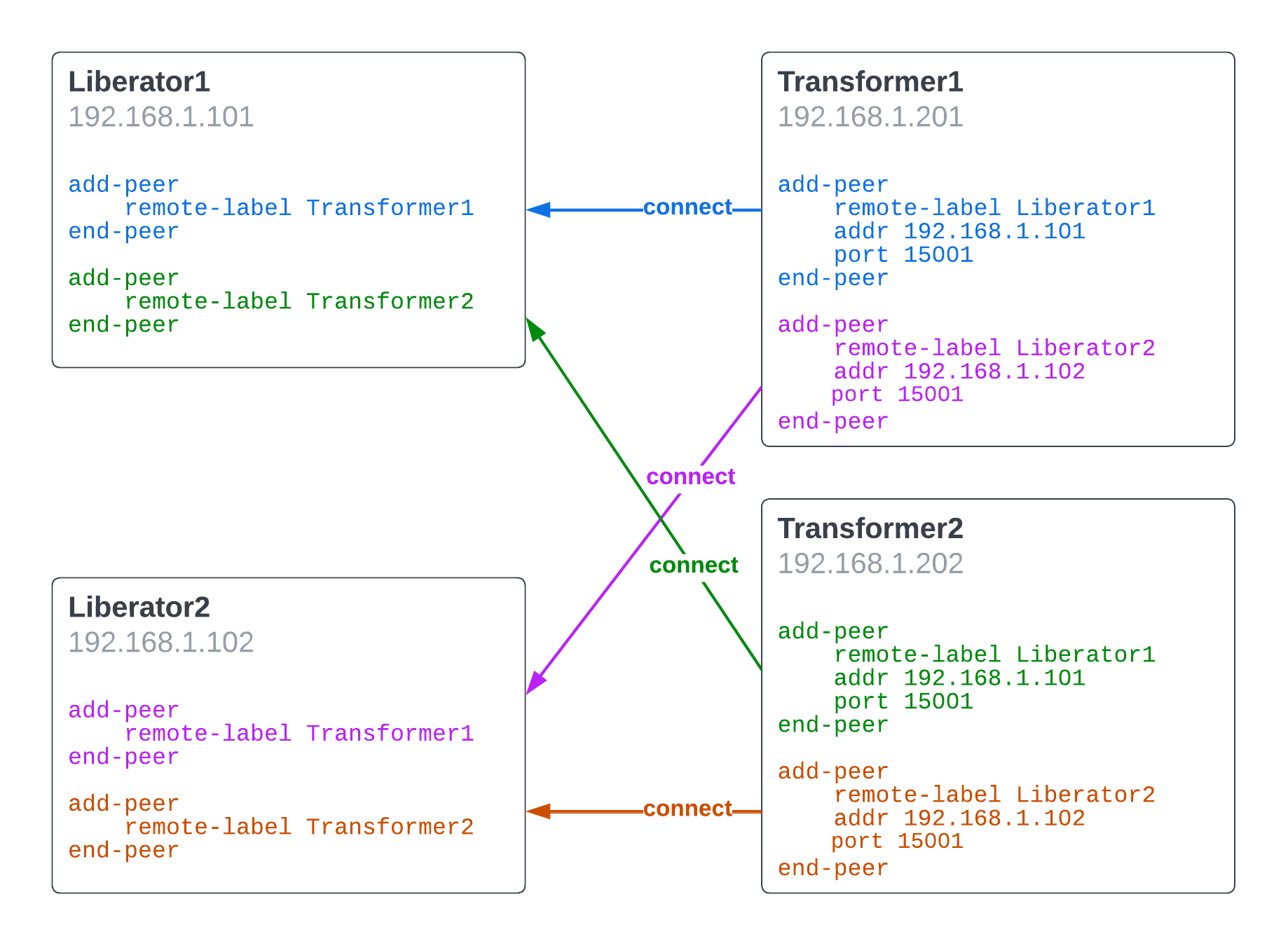
In a deployment that uses Discovery’s peer discovery, connections are not configured prior to deployment but discovered at runtime. Discovery maintains a register of DataSources in the deployment that includes their network locations, the data services they are configured with, and the data services they provide. Through this register, providing peers know which DataSources to connect to, and consuming peers know which DataSources to permit connections from.
The role of add-peer is replaced by discovery-provide-service service_name configuration in providing peers. A DataSource configured with discovery-provide-service service_name consults the Discovery register for DataSources configured with a data service named service_name and automatically connects to them.
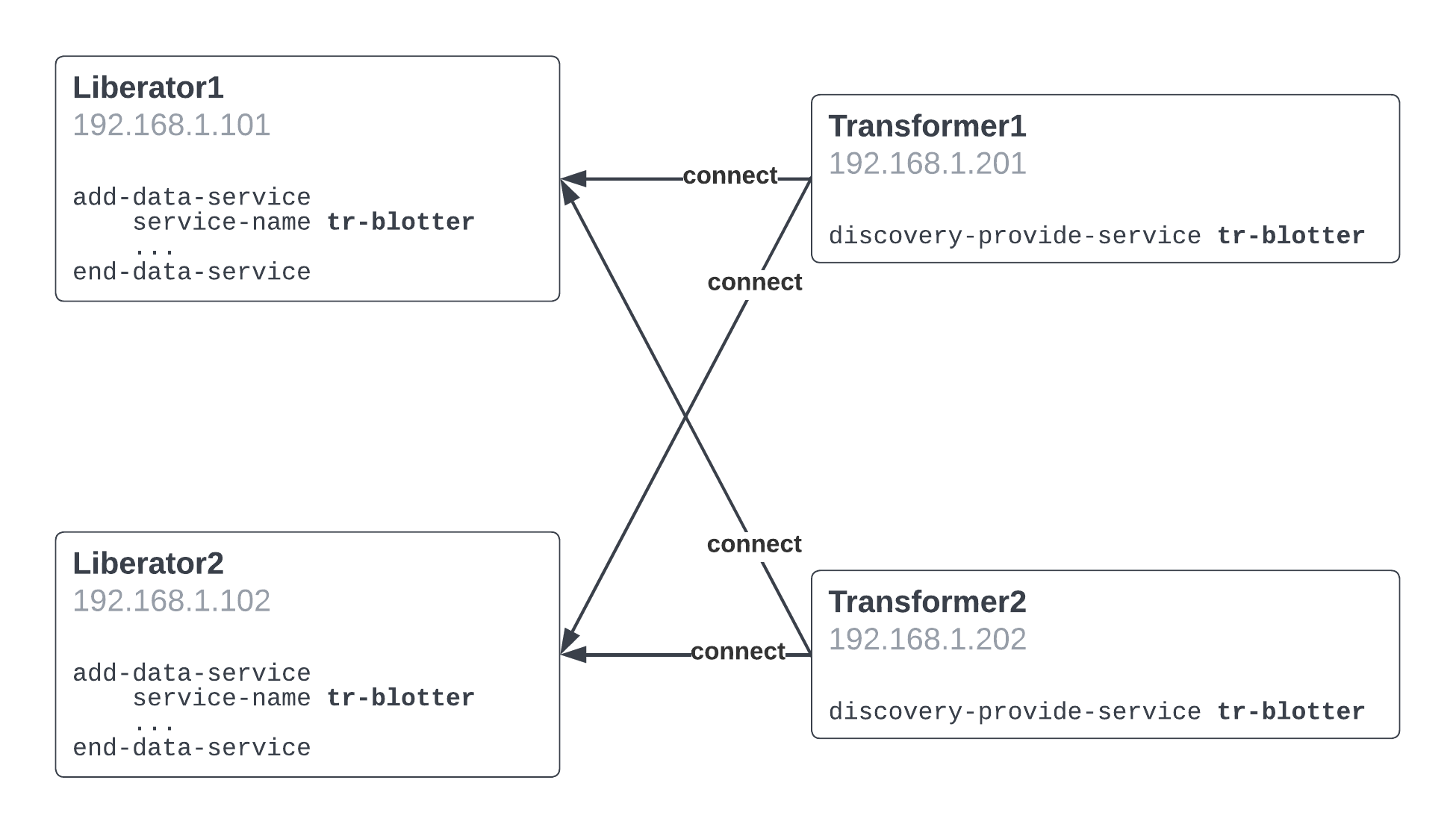
Peer discovery provides scalable peer connectivity, allowing you to add new component instances to a deployment at runtime without downtime for reconfiguration. However, for data services to take advantage of new component instances, you need Discovery’s scalable data services.
See also: