Subscribing to Data in the Platform
This page describes how the Caplin Platform connects to client applications, and maintains client sessions.
Connections and StreamLink
Caplin Liberator (part of the Caplin Platform) accepts connections from client applications that have been developed using the StreamLink API.

These connections can be made in a number of ways; the StreamLink API chooses the most appropriate connection type for the technology and software environment being used. If the client is a modern browser, StreamLink uses HTML5 WebSocket connections. When StreamLink runs in older browsers it applies various different techniques to establish a streaming connection to Liberator. Other types of (non-browser) application can also use StreamLink to connect, using either direct socket or HTTP(S)-based methods:
| Connection TYPE | SUPPORTED CLIENT |
|---|---|
WebSocket |
Java, Android applications, JavaScript, C/C++, iOS applications. |
HTTP Streaming |
Java, Android applications, JavaScript, C/C++, iOS applications, .NET applications. |
Direct |
Java, Android applications, C/C++, iOS applications, .NET applications. |
HTTP Polling |
Java, Android applications, JavaScript, .NET applications. |
Sessions and pub/sub
Liberator maintains client sessions, services subscriptions to data, and handles the publishing of messages. When a client application subscribes to data, Liberator has to retrieve a stream of data to supply to the client. This subscription may be for some common data that other clients are subscribed to, or it may be for some private data specific to the user. In both cases, if Liberator is not already subscribed to the stream of data it sends a subscription request to a Transformer or Integration Adapter that can supply the data. When the data is received from the Transformer or Integration Adapter, Liberator processes it and sends it on to all subscribed clients.

Client applications can also publish data to Liberator. Typically, the data is passed on to a suitable Transformer or Integration Adapter to be handled in a custom way. This technique is often used in trading applications to send trade messages from the client to a trading system.

Active Subscriptions
In a pure publish/subscribe model, publishers are completely isolated from subscribers. The only link between them is a component. What this means is that publishers have to constantly publish all their data. However, let’s say you have subscriptions for data that needs to be created dynamically. This publish/subscribe model does not always fit in with this style of the application. Implementations often attempt to work around this by arranging for publishers to subscribe to a known channel and listen for requests to start publishing data.
The Caplin Platform handles this style of subscription from the ground up. What this means is that when a client application subscribes to data, if that data is not already subscribed to by another client session, Liberator will send a subscription request to the relevant Integration Adapters. This allows the Integration Adapter to handle the subscription dynamically and create a custom data stream based on the subscription details.
Caplin calls this style of subscription an active subscription. It is not just a benefit for custom data streams; it also reduces traffic for standard data streams, as only the streams being subscribed to by clients need to be sent between Integration Adapters and Platform components.
The Caplin Platform also supports broadcasting of data, which can be useful in some cases, such as when an external data-supplying component only sends out data in a broadcast manner.
Augmenting your Application with Real-Time Data
You’ll know that most client applications have a 'presentation' part along with some data. Apps created in Caplin Platform are no different:
-
For a web app, the resources needed to run it are typically HTML, CSS, JavaScript, and images. These make up the 'presentation' part of the application. Both the presentation resources and the application logic are loaded from a traditional web stack that consists of web servers, application servers, and databases. On the other hand, for an installed application, the resources are usually compiled code in an executable form.
-
The data in the application is separate from the presentation. In a trading application, much of the data is updated in real time or is transient (there can also be historic data, but this is often updated in real time too). A trading application gets its data from the Caplin Platform by subscribing to it and receiving a stream of updates. It then uses the presentation logic to display the updated data to the end-user.
Take a look at the diagram below, which shows these two complementary stacks providing data to the same client application:
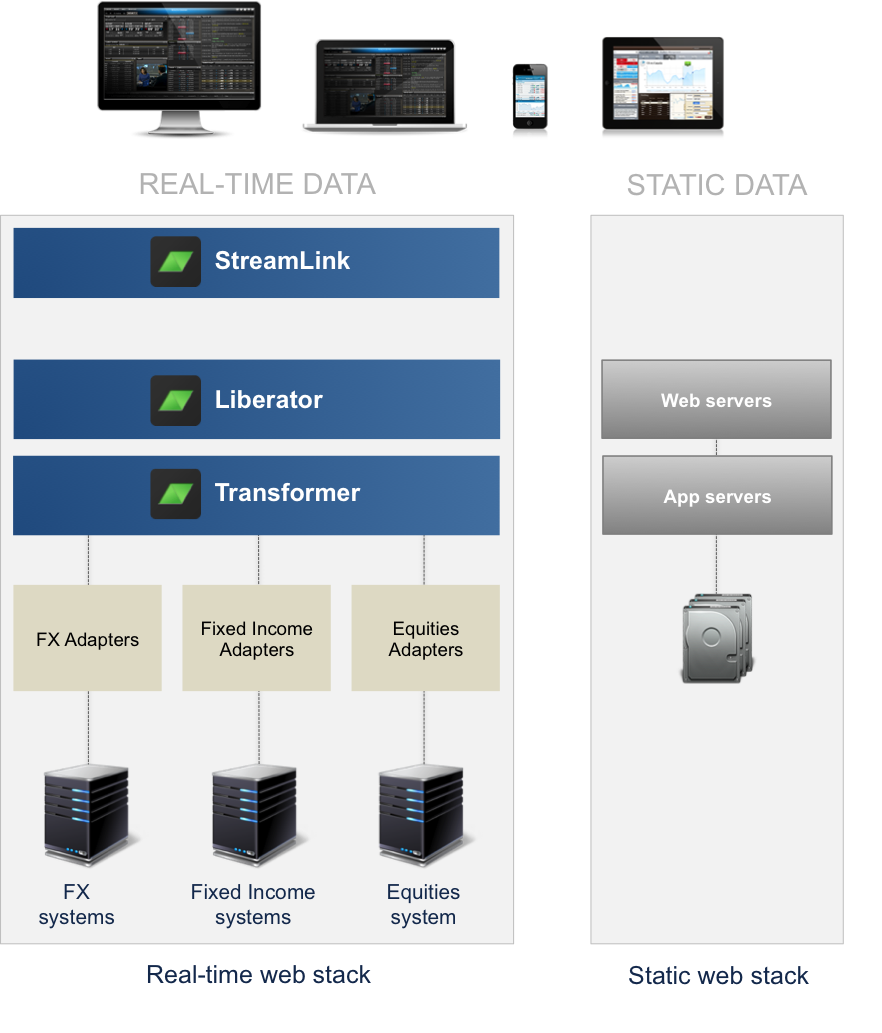
You’ll see that the web trading app gets its presentation logic and resources from a traditional web stack, and its data from the Caplin Platform. Because we split logic and resources, and data in this way you have much more flexibility in how you develop and deploy your app.
Now that you know all about how Caplin Platform subscribes to data, let’s take a look at how we can put the data into the Platform.