Data services
DataSource applications can obtain data from other DataSource applications through data services. By using a data service, your DataSource application can request objects based on their subject names without needing to know which other DataSource applications supply the objects.
Data services can be configured either statically or, from Platform 8, dynamically by other DataSource applications.
Dynamic data services
Since: Platform 8
Dynamic Services allows an adapter to provide Liberator and Transformer with routing configuration at the time of peer connection, with no downtime required for reconfiguration.
Dynamically provided data-services (add-provided-data-service) have a simpler specification than statically defined data-services (add-data-service):
| Option | Static | Dynamic |
|---|---|---|
Source groups ( |
1+ |
1 |
Priority sets ( |
1+ |
1 |
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
Notable differences:
-
Dynamic Services do not support source affinity. If you require source affinity, either use a statically defined data service or use Discovery, which supports source affinity in dynamic, scalable deployments.
-
Dynamic Services arranges adapter instances in one single-priority source group. Subject requests are load balanced across all adapter instances and automatically rebalanced when adapter instances are added or removed. To disable rebalancing for a provided data service, set the provided data service’s
service-typeoption tocontrib.
The adapter that sends the service definition doesn’t have to be the adapter that supplies the data.
A dynamic service cannot overwrite a static data service of the same name.
When new adapter instances connect and provide a dynamic service of the same name, the configuration options in the last adapter to connect apply. This means that an adapter could effectively override configuration set by earlier connecting instances.
In this example, a pricing adapter connects to Liberator using a Dynamic Peer connection and provides a configuration for PricingAdapter1 includes an outgoing peer connection and a provided data service.
Static data services
This section provides examples of static data service configuration. For more information on the configuration items used on this page, see Data services configuration.
Data service with one peer
Here’s some Liberator configuration that defines a data service:
# Single FX Pricing source
add-peer (1)
remote-name fxpriceadapter
remote-label fxpriceadapter
remote-type active
end-peer
add-data-service
service-name fx-prices (2)
include-pattern ^/FX (3)
add-source-group
required (4)
add-priority (5)
remote-label fxpriceadapter
end-priority
end-source-group
end-data-service
| 1 | Defines a single DataSource peer |
| 2 | Name of the data service |
| 3 | Regular expression describing which subjects are served by this service |
| 4 | A status stale message will be generated if a peer in this source group goes down |
| 5 | List of peers that serve the subjects in this service |
Data service with two peers (aggregated)
You can configure a data service to aggregate data from more than one source, by defining multiple source groups like this:
add-peer
remote-name fxpriceadapterA
remote-label fxpriceadapterA
remote-type active
end-peer
add-peer
remote-name fxpriceadapterB
remote-label fxpriceadapterB
remote-type active
end-peer
add-data-service
service-name fx-prices
include-pattern ^/FX
add-source-group
required
add-priority
remote-label fxpriceadapterA
end-priority
end-source-group
add-source-group
required
add-priority
remote-label fxpriceadapterB
end-priority
end-source-group
end-data-service
In this configuration, we’ve defined two DataSource peers, fxpriceadapterA and fxpriceadapterB, each supplying a different subset of FX instrument prices.
The data service configuration is split into two add-source-group sections, so that any subscription request whose subject starts with /FX is sent to both fxpriceadapterA and fxpriceadapterB at the same time.
Each Pricing Adapter subsequently sends Liberator the updates for its particular subset of FX instruments, and Liberator merges the updates together.
Because all the DataSource peers are subscribed to at once, this type of data service configuration is best used when the DataSource peer in each source group is responsible for supplying data for a subset of the subject range subscribed to. In the above example, if fxpriceadapterA and fxpriceadapterB each handled all of the /FX instruments, rather than a subset, Liberator would receive duplicate updates for every FX instrument, which would waste communication bandwidth and processor resources.
Data service with two peers (load-balanced)
You can deploy multiple instances of an Integration Adapter, each supplying the same data, so that no individual Adapter becomes overloaded.
| If more peers are deployed than are required to service the average workload, then load balancing also provides an element of redundancy and failover. |
There are two available algorithms for distributing subscriptions across adapter instances:
-
Default algorithm: load balancing based on number of subscriptions. The data service routes each new subscription to the adapter instance with which the data service has the least number of subscriptions.
-
Source affinity: load balancing based on subject substring. A new subscription is distributed to an adapter instance based on a numeric hash of a substring extracted from the subscription subject (usually the username) prefixed with the source group’s affinity key. Subscriptions that resolve to the same numeric hash show an affinity for the same adapter instance.
Default load-balancing algorithm
Load balancing by adapter workload is the default algorithm for load balancing.
# Load balanced FX pricing sources
add-peer
remote-name fxpriceadapter1
remote-label fxpriceadapter1
remote-type active
end-peer
add-peer
remote-name fxpriceadapter2
remote-label fxpriceadapter2
remote-type active
end-peer
add-data-service
service-name fx-price
include-pattern ^/FX
add-source-group
required
add-priority (1)
remote-label fxpriceadapter1
remote-label fxpriceadapter2
end-priority
end-source-group
end-data-service
| 1 | To load-balance by adapter workload, list adapter instances in the add-priority block. |
In this configuration we’ve defined two DataSource peers, fxpriceadapter1 and fxpriceadapter2. They each supply the same set of FX instrument prices.
The add-priority block within the fx-prices data service refers to these two peers. This tells the data service to route each FX subscription request to whichever of fxpriceadapter1 and fxpriceadapter2 is serving the least number of subscriptions to the data service, so it balances the load across these two Pricing Adapters.
| You can load balance across an arbitrary number of DataSource peers, subject to performance considerations. See Caplin Platform System Requirements. |
If the selected peer returns a NODATA DataSource packet with either the NotFound or Unavailable flag set, then the DataSource tries each of the selected peer’s siblings in the add-priority block until either it finds a peer that can serve the subject or it exhausts the number of available peers in the block.
If a peer in a data-service’s add-priority block disconnects, then the peer’s subscriptions are distributed across the remaining peers in the add-priority block. When the peer comes back online, by default the data-service does not give the returning peer a share of the existing workload. Instead, the returning peer, as the peer with the least workload, receives all new subscription requests until workload is balanced across peers. If you want the returning peer to take on a share of the data-service’s existing subscriptions, then enable service rebalancing (see service-rebalance-enable and rebalance-enable).
Load-balancing adapter instances in this way also offers an element of redundancy if you deliberately run more adapter instances than required to serve the expected workload.
The default load-balancing algorithm is compatible with an adapter if subscriptions served by the adapter can be served by any instance of that adapter. If an adapter maintains session state or a cache, or two or more of a user’s subscriptions must be served by the same instance of the adapter, then enable source affinity (next section).
Source affinity load-balancing algorithm
Source affinity is an alternative load-balancing algorithm that routes a new subscription to an adapter instance based on a numeric hash of a substring of the subscription subject prefixed with a constant (the 'affinity key') defined at source group level. Subscriptions that resolve to the same numeric hash are routed to the same adapter instance.
The most common use case for source affinity is to ensure that a user’s subscriptions to subjects served by an adapter are served by the same instance of that adapter. In this use case, the substring extracted from subscriptions is a username.
Service rebalancing (see service-rebalance-enable and rebalance-enable) is automatically disabled for any subscriptions subject to source affinity.
For a detailed look at source affinity and an illustrated worked example, see Load-balance adapters using source affinity.
Data service with two peers (failover)
You can configure a data service so that it will connect to an alternative DataSource peer if the first choice of peer goes down (becomes unavailable). This technique is called failover. Here’s an example:
# Failover of FX Pricing sources
add-peer
remote-name fxpriceadapter1
remote-label fxpriceadapter1
remote-type active
end-peer
add-peer
remote-name fxpriceadapter2
remote-label fxpriceadapter2
remote-type active
end-peer
add-data-service
service-name fx-prices
include-pattern ^/FX
add-source-group
required
add-priority
remote-label fxpriceadapter1
end-priority
add-priority
remote-label fxpriceadapter2
end-priority
end-source-group
end-data-service
Once again we have two Integration Adapters that supply the same FX data: fxpriceadapter1 and fxpriceadapter2.
The definition for the fx-prices data service declares that the two adapters are in separate priority groups. The order of the priority groups determines the failover priority. So, when the Liberator starts up, it routes all subscriptions to fxpriceadapter1 (provided this Adapter is up and running). If fxpriceadapter1 becomes unavailable, then the Liberator reroutes all subscriptions to fxpriceadapter2. When fxpriceadapter1 comes back online, existing subscriptions continue to be served by fxpriceadapter2, but new subscriptions are routed to fxpriceadapter1.
If you wanted your FX pricing data stream to be extremely resilient, you could have three, or even more, FX Pricing Adapters and configure a separate priority group for each one, so that the Liberator could fail over to each Adapter in turn.
More than one adapter can be included in each add-priority group. Adapters within each add-priority group are load-balanced. If an Adapter fails within an add-priority group, then the failed adapter’s subscriptions are reallocated to the remaining adapters in the add-priority group. If all adapters within an add-priority group fail, then all the add-priority group’s subscriptions failover to the next add-priority group of adapters.
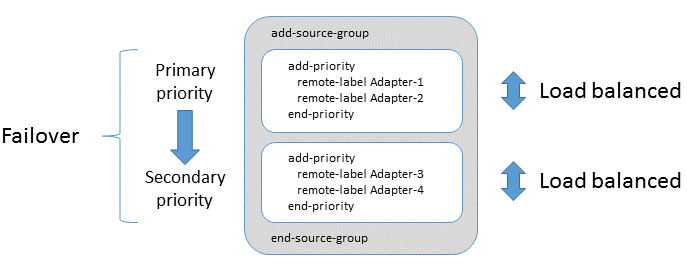
Failover is a suitable configuration for all data services except those that route subscriptions for trade and blotter channels. Because of relative differences in subscription persistance between trade and blotter subscriptions, an edge case can arise during recovery of a failed Trading Adapter instance when a user’s trade and blotter subscriptions can be routed to different instances of the Trading Adapter. A user’s trade channel subscriptions and blotter channel subscriptions must be routed to the same Trading Adapter instance; see source affinity above.
| Don’t use failover for data services that route updates on trade channels or blotter channels; use load balancing with source affinity instead. |
Data services with minimum requirements for peer availability
From C DataSource API 7.1.6, Liberator 7.1.5, and Transformer 7.1.5, you can configure minimum levels of availability within a data service.
Minimum number of available peers
Requests served by a priority group are load-balanced among the peers in the priority group. By default, only one peer has to be available for the priority group to be marked as available. To increase this minimum threshold, use the min-peers option.
In the example below, a priority group has three load-balanced peers. The system architect has determined that at least two peers are required to provide an adequate service level, so the min-peers option has been set to 2. If this minimum threshold is not met, the DataSource marks the priority group as unavailable.
add-data-service
service-name fx-price
include-pattern ^/FX
add-source-group
add-priority
min-peers 2
remote-label adapterA
remote-label adapterB
remote-label adapterC
end-priority
end-source-group
end-data-serviceMinimum number of available priority groups
Requests served by a source group are routed to the first available priority group. By default, only one priority group has to be available for the source group to be marked as available. To increase this minimum threshold, use the min-priorities option.
In the example below, a source group contains three priority groups. The system architect has stipulated that the source group can only be marked as available if there are at least two priority groups available, so the min-priorities option has been set to 2. If this minimum threshold is not met, the DataSource marks the source-group as unavailable.
add-data-service
service-name fx-price
include-pattern ^/FX
add-source-group
min-priorities 2
add-priority
...
end-priority
add-priority
...
end-priority
add-priority
...
end-priority
end-source-group
end-data-serviceMinimum number of available source groups
Requests served by a data service are routed to all source groups in the data service. By default, only one source group has to be available for the data service to be marked as available. To increase this minimum threshold, use the min-source-groups option.
In the example below, a data service routes requests to three source groups. The system architect has stipulated that the data service can only be considered available if all three source groups are available, so min-source-groups has been set to 3. If this minimum threshold is not met, the DataSource marks the data service as unavailable.
add-data-service
service-name fx-price
include-pattern ^/FX
min-source-groups 3
add-source-group
...
end-source-group
add-source-group
...
end-source-group
add-source-group
...
end-source-group
end-data-serviceUsing data services in your own DataSource applications
As we have seen above, Liberator makes extensive use of data services, and so does Transformer. You can also configure data services into your own C-based DataSource applications that have been built using the DataSource C API, and into .NET-based DataSource applications built with the DataSource.NET API.
Data services aren’t available in Java-based applications built with the Caplin Integration Suite, but this isn’t really a problem because you normally use the Caplin Integration Suite to implement Integration Adapters that supply data to the Caplin Platform (Liberator or Transformer), rather than subscribing to data themselves.
See also:
-
Reference: Data services configuration
-
Reference: DataSource peers configuration
-
How can I… Load-balance adapters using source affinity