Transformer architecture
Here’s the internal architecture of Caplin Transformer:
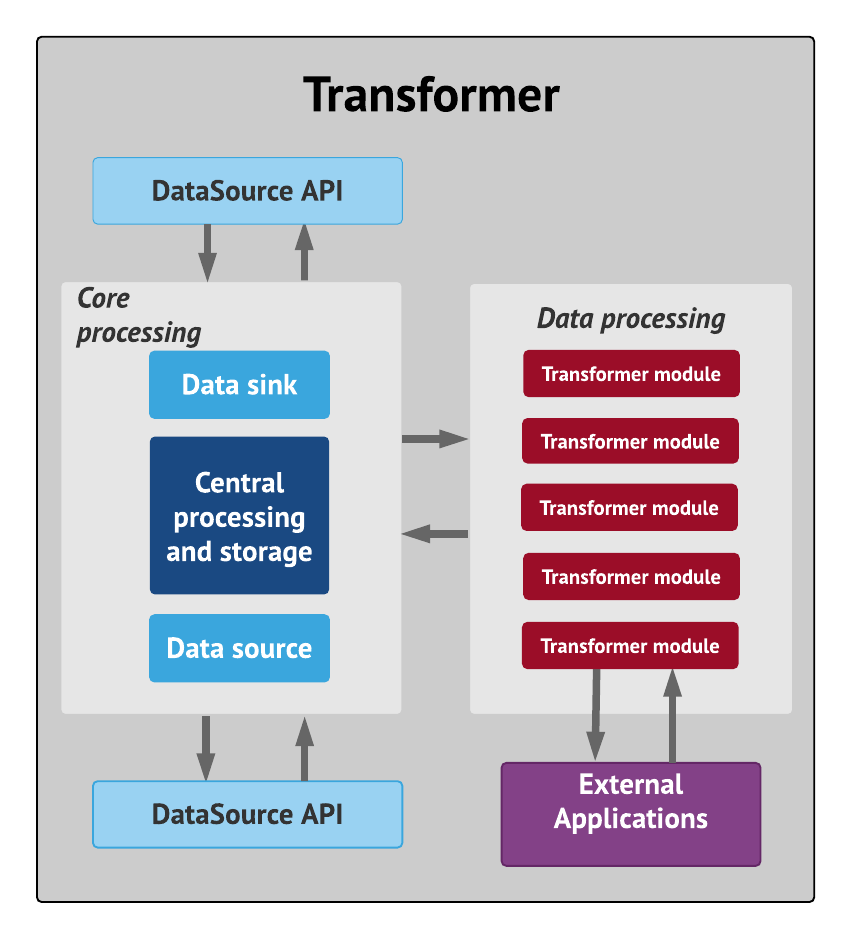
Transformer’s a DataSource application, just like Liberator and the Integration Adapters deployed in the Caplin Platform.
-
It receives data from other DataSource applications, typically:
-
Integration Adapters (for example, a Pricing Adapter that feeds Transformer with raw price information),
-
other Transformers (for example, when you have a lot of data transformations to make and you want to split them between Transformers in addition to splitting them between modules within a Transformer),
-
or even a Liberator that publishes data supplied by clients (see Client publication).
-
-
The Data sink element of Transformer extracts the incoming data, via the DataSource API.
-
The Central processing element sends the data for each incoming subject to the relevant Transformer module(s), which execute the specific algorithms that transform the data. Central processing also maintains a cache of the data.
-
The amended data is either output to one or more external applications, such as databases used to store historical records, or it’s sent back to the Transformer core.
-
Once back in the core, the Data source element sends the amended data out, via the DataSource API, to other subscribing DataSource applications. These would typically be:
-
Liberator (which pushes the data through to client applications via StreamLink),
-
other Integration Adapters (which would publish the amended data to an external system),
-
or even other Transformers.
-
See also:
-
Features and Concepts: Platform Architecture
-
Features and Concepts: Transformer modules
-
Features and Concepts: DataSource concepts